
Robots txt. Зачем нужен robots txt. Как создать файл
Что такое Robots.txt и поисковые роботы
Что будет с сайтом без Robots.txt
Что такое Robots.txt и поисковые роботы.

Robots.txt — текстовый файл, который содержит параметры индексирования сайта для роботов поисковых систем. Поисковые роботы — «пауки», «краулеры» это программы, которые «приходят» на Ваш сайт, загружают и «просматривают» страницы, делают «специальные» копии этих страниц и помещают их в базу поисковой системы. Содержание страницы анализируется, выделяются ключевые слова, заголовки, ссылки и т.д. Можно посмотреть в каком виде эти копии хранятся в базе поисковой системы.
![]()
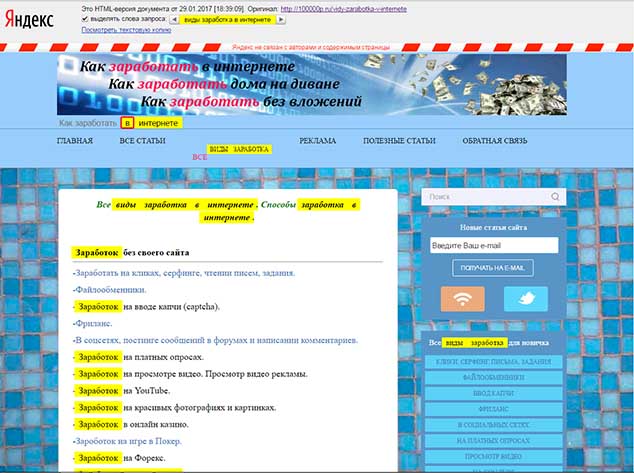
У каждой поисковой системы свои «поисковые роботы». У Яндекса их много: YandexBot, YandexDirect, YandexDirectDyn, YandexMedia, YandexImages, YaDirectFetcher, YandexBlogs, YandexNews, YandexPagechecker, YandexMetrika, YandexMarket, YandexCalendar (подробнее на странице Яндекс «Использование robots.txt» ).
Основные из них:
«YandexBot» — основной индексирующий робот.
«YandexImages» — индексатор Яндекс.Картинок.
«YandexMedia» — робот, индексирующий мультимедийные данные.
Похожие поисковые роботы у Google:
Googlebot (Google Поиск), Googlebot News, Googlebot Images, Googlebot Video, Google Smartphone, Google Mobile AdSense, Google AdSense, Google AdsBot (подробнее на странице Google « поисковые роботы Google» ).
Googlebot — основной поисковый робот от Google. Он обнаруживает и добавлять в индекс Гугл новые или измененные страницы.
Googlebot Images — индексатор Картинок.
Googlebot Video — робот, индексирующий видео файлы.
Где находится Robots.txt.
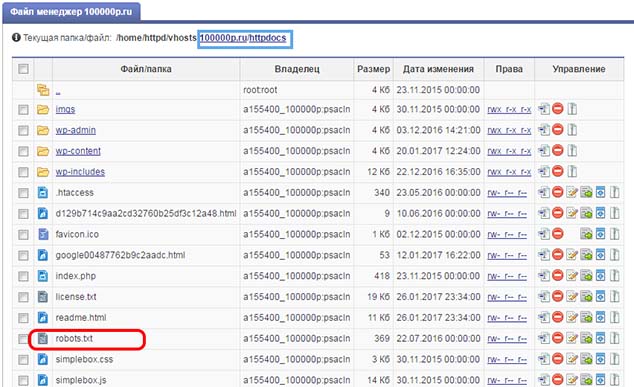
Файл Robots.txt находится в Корневом каталоге Вашего сайта /имя домена/httpdocs, его можно увидеть зайдя на Ваш Хостинг.
![]()
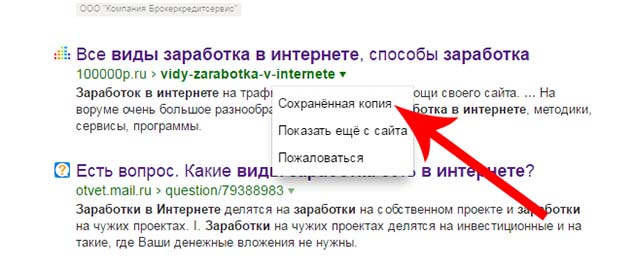
Можно ввести ссылку http://имя домена/robots.txt и увидеть Ваш файл robots.txt в том виде, в котором его видят «поисковые роботы».
Если введя адрес — файл не появился, значит его нет.
Что будет с сайтом без Robots.txt.
Теоретически все будет работать и без файла Robots.txt. Робот начнет загружать файл, если он отсутствует или не является текстовым(не читается), «поисковый робот» проиндексирует весь сайт, все страницы, все картинки, абсолютно все — что найдет. Т.е посчитает, что доступ к файлам не ограничен. «Притащив» копии новых страниц в базу поисковой системы, робот укажет в отчете об отсутствии на сайте файла Robots.txt. Каждый раз, робот будет тратить драгоценные секунды на поиск файла Robots.txt на Вашем сайте. Наличие Robots.txt на сайте это как «свидетельство о рождении», нет документа — Вы неполноценный гражданин, нет Robots.txt на сайте — неполноценный сайт. Также в robots.txt указывается путь к файлу sitemap.xml, а этот файл не менее важен. Далее, когда Вы зарегистрируйте свой сайт в Вэбмастер Яндекс или Вэбмастер Гугл после сканирования сайта будет выдаваться ошибка — «отсутствует Robots.txt». Любая программа для анализа сайта тоже всегда будет «кричать», что нет файла Robots.txt.
Как создать Robots.txt.
Файл создается в простом файловом редакторе — в «Блокноте».
![]()
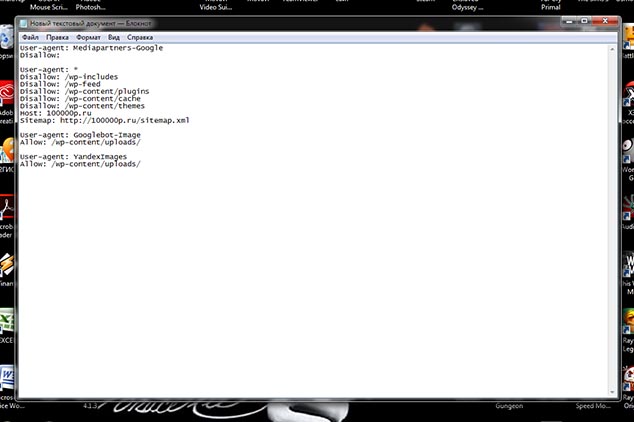
Файлу необходимо дать имя robots и сохранить в формате txt.
![]()
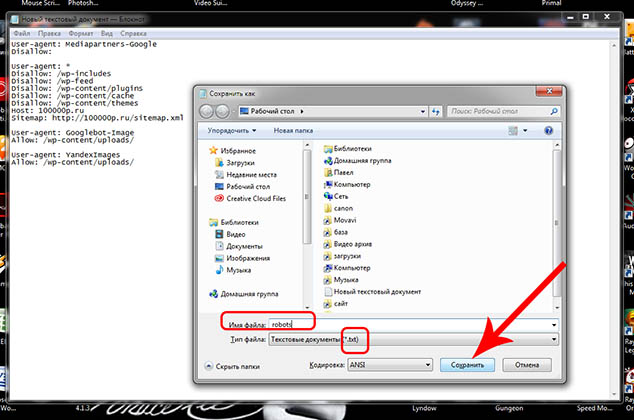
Можно убедиться, правильно ли Вы его сохранили
![]()
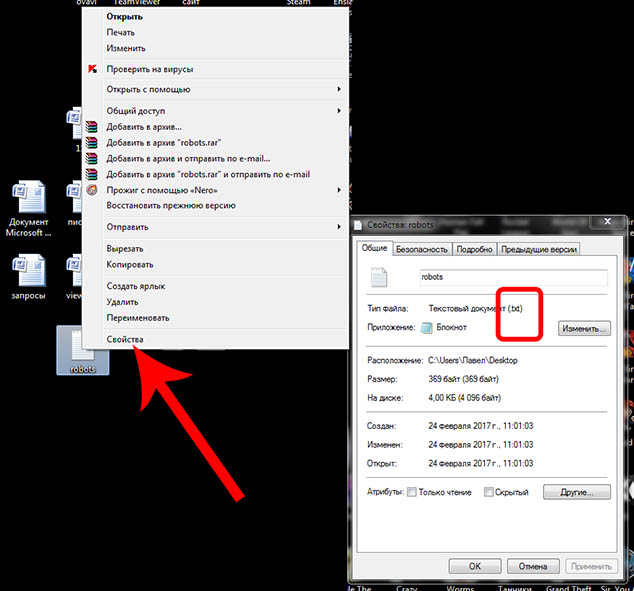
Затем его необходимо закинуть в корневой каталог сайта (на Хостинге). Потом заходите в Вэбмастер Яндекс - Анализ robots.txt, введите содержание текста файла и проанализируйте .
![]()
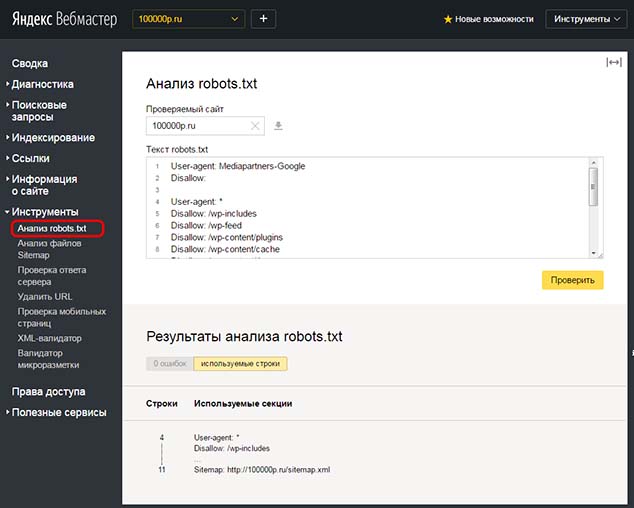
Получите отчет о наличии ошибок в файле. Можно вбить адрес любой страницы и убедиться, что она доступна для индексирования или наоборот.
![]()
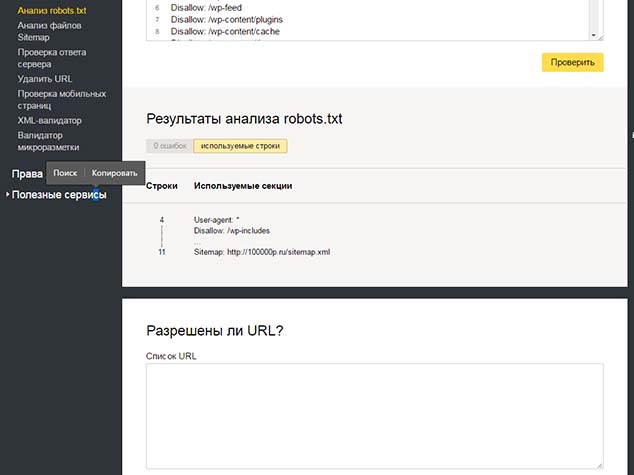
В Вэбмастер Гугл также есть инструмент проверки файла robots.txt.
![]()
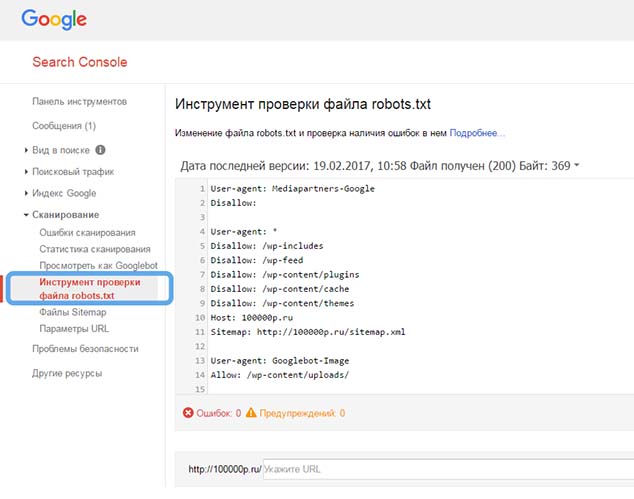
После проверки файла в Вэбмастер Яндекс, Вэбмастер Гугл «ошибка об отсутствии файла» пропадет из отчета.
Содержание сайта.
Прежде чем говорить о содержании файла robots.txt, давайте посмотрим из чего состоит Ваш сайт, зайдем в корневую директорию /имя домена/httpdocs
![]()
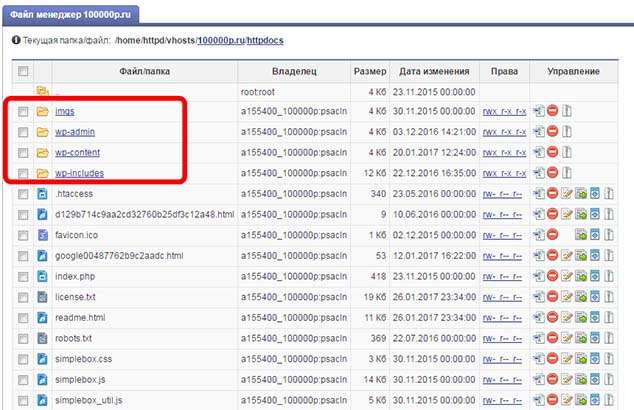
Корневой каталог содержит папки imgs, wp-admin, wp-content, wp-includes и различные PHP файлы.
wp-admin — само название выдает суть папки WordPress- admin...эта папка содержит файлы отвечающие за конфигурацию консоли и административной панели WordPress.
wp-content — папка wp-content содержит все что пользователь загрузил на сайт cache (кэш), languages(языковые файлы), logs(логи) , plugins(загруженные плагины), themes(темы шаблона сайта), upgrade(апгрейд), uploads (все ваши загруженные картинки, мультимедия).
wp-includes — файлы обеспечивающие работу движка WordPress.
Где же хранятся страницы и записи сайта. Оказывается «физически» они не существуют, файл со страницей нельзя найти на Хостинге, открыть, посмотреть и «пощупать». Данные о содержании страницы, о тексте, о шрифте, структуре содержатся в Базе данных MySQL. При запросе к адресу страницы они автоматически формируются «Движком сайта». Зачем так сделано? А представьте если бы файл страницы существовал «физически» и его открыл «первый посетитель», а затем бы открыл второй...что бы было... наверное он получил ,бы ответ, что страница занята и просматривается другим посетителем. Но движок сайта смог бы сгенерировать копию страницы для второго посетителя... наверное да...но если 10 посетителей...100 посетителей одновременно просматривают запись или страницу? Поэтому формировать страницы логичнее, в зависимости от имеющихся запросов. Я клоню к тому, что информация указываемая в robots.txt обычно касается папок корневого каталога, про страницы и записи там нет информации. Поисковый робот найдя новую ссылку (в sitemap.xml или придя по ней с другого сайта) «загрузит страницу» она сформируется на его запрос и он проанализирует ее. Можно конечно указать в robots.txt адрес конкретной страницы и запретить ее индексирование, но так делают редко, легче ее «не публиковать», оставить в черновиках и т.д.
Содержание файла.
Файл начинается с записи User-agent.
User-agent: YandexBot — информация для основного индексирующего робота Яндекс.или
User-agent: Yandex — информация для всех индексирующих роботов Яндекс.или
User-agent: * — информация для всех индексирующих роботов.
Тоже самое User-agent: Googlebot — информация для основного индексирующего робота Гугл.
Затем следуют директивы Disallow: (скрыть — не индексировать) и Allow:(показать — индексировать)
Например:
User-agent: Yandex
Disallow: / - запретить индексирование всего сайта поисковому роботу Яндекс
Другой пример:
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: / — запретить все кроме «загруженных картинок, мультимедия»
Если в директиве Disallow: нет информации (после : ничего не написано)
User-agent: Yandex
Disallow: — значит это будет расценено как
Allow: / — индексировать все
Затем добавляется директива Host.
Host: имя домена — в ней указывается основной сайт для зеркал Вашего сайта.
Затем добавляется директива Sitemap.
Sitemap: http://имя домена/sitemap.xml — указывается путь к файлу sitemap.xml.
Робот посетив сайт, запомнит путь к файлу и будет его использовать при последующих посещениях.
Рассмотрим примеры файла robots.txt.
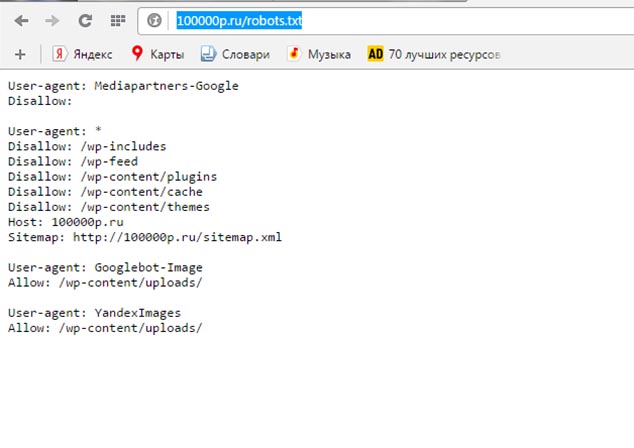
User-agent: * — для всех поисковых роботов
Disallow: /wp-includes — не индексировать папку
Disallow: /wp-feed — не индексировать папку
Disallow: /wp-content/plugins — не индексировать папку
Disallow: /wp-content/cache — не индексировать папку
Disallow: /wp-content/themes — не индексировать папку
Host: 100000p.ru — указание основного сайта при наличии зеркал
Sitemap: http://100000p.ru/sitemap.xml — путь к файлу sitemap.xml
— пробел обязательно ставится между директивами User-agent:
User-agent: Googlebot-Image — разрешить роботу гугл индексировать картинки
Allow: /wp-content/uploads/
— пробел обязательно ставится между директивами User-agent:
User-agent: YandexImages — роботу Яндекс
Allow: /wp-content/uploads/ — разрешить индексировать картинки
Можно зайти на любой сайт, к блогеру сайт которого Вам нравится, которого читаете и позаимствовать (скопировать) файл у него http://имя домена/robots.txt.
Это сделать можно, но не желательно, т.к там могут быть указаны пути к папкам которых просто нет у Вас и робот каждый раз будет заходить к Вам на сайт, читать robots.txt и зависать на секунды, не находя нужного пути, нужной папки.
![]()
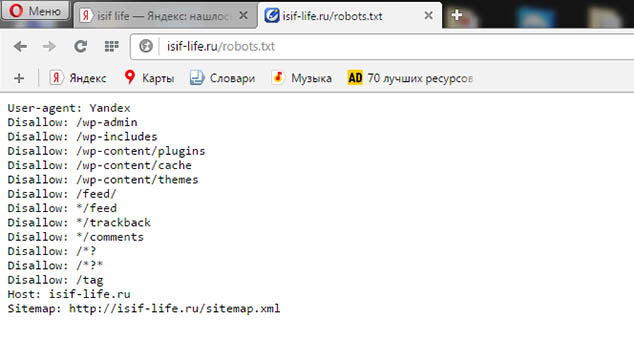
Отсюда делаем вывод: что лучше взять чей то файл за образец и откорректировать его, удалить то что Вам не нужно или подробно прочитать инструкции по созданию файла robots.txt в Яндекс и Гугл и написать свой.
Самый простой файл.
User-agent: *
Allow: /
Host: имя домена
Sitemap: http://имя домена/sitemap.xml Всем все разрешить индексировать.

 Хочешь получать статьи этого блога на почту?
Хочешь получать статьи этого блога на почту?





Добавить комментарий